(See also our mathematical notation page)
Basics
Given a system model, an initial system state, and a sequence of noisy measurements, a Kalman filter can be constructed to produce a sequence of state estimates that are optimal in the sense that they minimize the expected square-error between the estimates and the true system state.
Summary of Kalman Filter Symbols
|
||||||||||||||||||||||||||||||||||||||||||
|
Table (1) |
Typical Kalman Filter Equations
|
||||||||||||||||
|
Table (2) |
![\bf{\hat x_0} = \it E[\bf{x_0}]](./145a75e000e9a6968a0eb46400b3ebaf.png)
![\bf{P_0} = \it E[(\bf{\hat x_0 - x_0})^2]](./c20483b07842ee89031a3242474b6729.png)
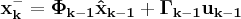
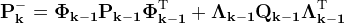
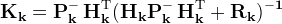
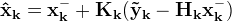
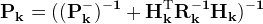
Start with the discreet linear dynamic system equation
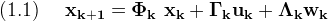
And the measurement equation
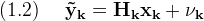
Where the subscript (·k) indicates the value at time step (tk)
Although the form of the system equations would seem to apply only to strictly linear systems, as usual, various linearizations and quasi-non-linear techniques can be applied to extend the Kalman filter to a variety of real world non-linear problems.
Making some key assumptions will greatly simplify what follows.
Assume that
- For each time step (k); (Φk), (Γk), (Λk), (Hk) and (uk) are known without error
- Noise components (wk) and (νk) are uncorrelated Gaussian random sequences with zero mean
- The noise covariance matrices are known, (cov[wk]=Qk), (cov[νk]=Rk)
In principle these assumptions can be relaxed somewhat. For example, if any of the system matrices contain random components, those components may be factored out into the noise vectors. Similarly, any noise process that is representable as a linear combination of white Gaussian noise can be modeled by adding extra states to the system and driving those extra states with zero mean Gaussian noise. Even if the noise matrices are not known exactly, they can be estimated, or calculated on line, or discovered by system tuning.
The exact quantity minimized by a Kalman filter is the matrix (P), the state error covariance matrix
![\displaystyle (1.3)\quad\
\bf{P} \equiv \it{E}[\bf{(\hat x-x)}^2]](./df0f53d0f13c473b4e0bfafbc05585fb.png)
Where (E ) is a function returning the expectation of a random variable
The estimated state (x̂) that minimizes (P) is found by solving a weighted least squares problem. The weights for the computation ultimately come from the process noise covariance matrix (Q) and the measurement noise covariance matrix (R). The actual output of the filter is a sequence of linear combinations formed from the predicted state (x⁻), and the current measurements of the system (ỹ). Technically these outputs are known as the best linear unbiased estimates. The existence of such estimates is guaranteed only with certain restrictions, see the section on complications. (FIXME: complications section not built yet)
Typically the Kalman filter is implemented recursively as a predictor-corrector system. In the prediction step, knowledge of the past state of the system is used to extrapolate to the system's state at the next time step. Once the next time step is actually reached and new measurements become available, the new measurements are used to refine the filter's estimate of the true state like this
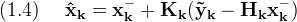
Where the matrix (Kk), the Kalman gain, or feedback matrix, is chosen so that (Pk) is minimized
Later there will be some justification, but for now accept that one possible choice for (Kk) is
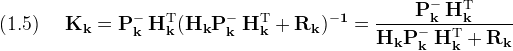
Where the measurement noise covariance matrix (Rk) is defined as
![\displaystyle (1.6)\quad\
\bf{R} \equiv \mbox{\rm cov}[\bf{\nu}] = \it E[\bf{\nu}^2]](./998029050058636caf786fdb71f6f5a3.png)
The relative magnitudes of matrices (Rk) and (Pk) control a trade-off between the filter's use of predicted state estimate (xk⁻) and measurement (ỹk).
Consider some limits on (Kk)
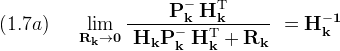
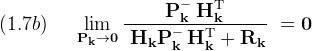
Substituting the first limit into the measurement update equation (1.4) suggests that when the magnitude of (R) is small, meaning that the measurements are accurate, the state estimate depends mostly on the measurements. Likewise when the state is known accurately, then (H P⁻ HT) is small compared to (R), and the filter mostly ignores the measurements relying instead on the prediction derived from the previous state (xk⁻).
Example
Derivation
The desired Kalman filter implementation is linear and recursive, that is, given the old filter state (𝓕k-1) and new measurements (𝓜k) the new filter state is calculated as
![\displaystyle (3.1a)\quad\
{\cal F}_k^- = \it g [{\cal F}_{k-1}]](./3180df4f4b891f8cb2962c7e59d621a4.png)
![\displaystyle (3.1b)\quad\
{\cal F}_k = \it f [{\cal F}_k^-\,,\ {\cal M}_k]](./99e921aee3c97f1a82d55dda886abddd.png)
Where ( f and g ) are linear functions
Referring to table(2), the sequence of equations shown are both linear and recursive as desired. Though so far, little explanation has been given to justify their use. In order to maintain some credibility, and to prove we aren't total mathematical wimps, we will attempt a derivation of these equations. The goal here is not mathematical perfection, rather clarity without serious error.
Fundamentally Kalman filtering involves solving a least squares error problem. Specifically, given a state estimate (x⁻) of known covariance (P⁻) and a new set of measurements (ỹ) with covariance (R), find a new state estimate (x̂) such that the new state error covariance (P) is minimized.
For the predicted state error write
![\displaystyle (3.2)\quad\
\bf \mbox{\rm cov}[\bf{x^- - x}] = \bf P^-](./00add60e064635d593963eab97f3dea1.png)
Likewise for the measurement error
![\displaystyle (3.3)\quad\
\bf \mbox{\rm cov}[\bf{\tilde y - y}] = \bf R](./e7c47df7b06b6f69930905acfd1017bf.png)
Seek a new state vector (x̂) such that the (n+m×1) combined state error vector
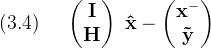
Is minimized in the weighted least squares sense
The chief difficulty with Kalman filter theory is contained in (3.4). The errors in (3.2) and (3.3) are defined in terms of the true state and exact measurements, but while operating the filter, all that is available are estimates and noisy measurements. In equation (3.4) the measurement (ỹ) and the estimated state (x⁻) have been used where the exact values would seem to be appropriate. Here's a simple-minded explanation of why it's ok to use the imprecise values in (3.4): The noise has been assumed to be zero-mean, therefore the expectation of the approximate values are the correct true values, so using the approximate values will produce unbiased estimates. Further, since it has been assumed that the covariance of both (ỹ) and (x⁻) are known, the weighted least squares process has enough information to properly minimize the total square error.
Whether the previous paragraph constitutes a satisfactory justification of (3.4) is a question worth pondering. If not there are many, many, many, books that address this issue (try looking up stochastic least squares). (However the chances of finding a very clear explanation appear to be low.) The issue is significant in as much as once (3.4) is accepted, Kalman filtering as a theoretical matter is essentially solved. Though, solved in this sense is still far from a practical implementation. To derive a practical filter, some clever arithmetic is required.
A weighted least squares solution minimizes a scalar cost function (𝓙), here written in matrix form
![\displaystyle (3.5)\quad\
\cal{J}[\bf \epsilon , \bf W] = \bf{\epsilon}^{\rm T} \, \bf W \, \bf \epsilon](./b3fa7d89cea2b81514a1fda70d7855a1.png)
Where the matrix (W) is the weighting for the cost function. The weighting can be any positive definite matrix.
In formulating the Kalman filter the noise statistics have been defined in terms of covariance, and since elements with large covariance should be given low weight, the correct weighting matrix for this problem is the inverse of the covariance matrix. This is appealing intuitively and not too difficult to prove, though no proof is given here.
Using the inverse covariance as the weighting function and referring to (3.4) the cost function for the Kalman filter is
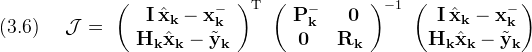
Where the block matrices shown have dimensions (n+m×1) and (n+m×n+m) respectively
The notational mapping suggested by (3.4) is
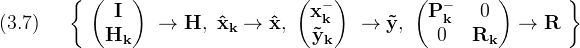
Use this mapping to state the cost function in a slightly more generic form as
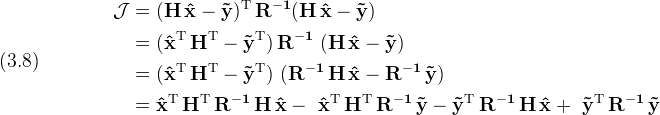
In (3.8) the cost function has been expanded in anticipation of taking derivatives. (A matrix derivative typically involves taking a transpose.)
Returning to the generic minimization problem, take the partial derivative
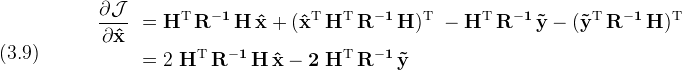
Set the derivative to zero and solve for (x̂)
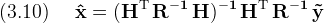
This is the classic weighted least squares solution.
Applying (3.10) to our original problem using (3.7) gets
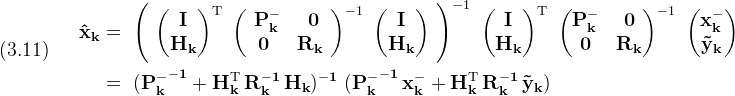
There's nothing wrong with the form given in (3.11), but for various reasons it's desirable to exhibit the measurement update form (1.4). To do this everyone uses the matrix inversion lemma
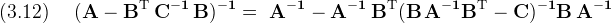
Using the mapping
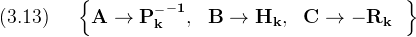
The solution given by (3.11) becomes
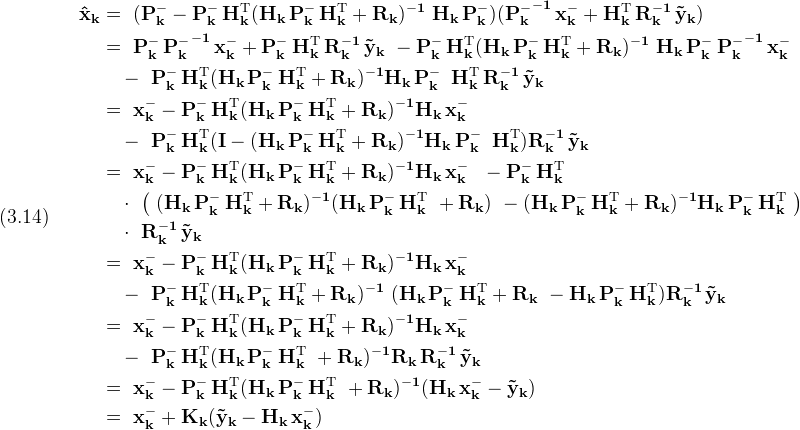
Which matches the measurement update form given in (1.4) with (Kk) as in (1.5)
It's possible to derive the state error update equation directly from the definition given in (1.3) and repeated here
![\displaystyle (3.15)\quad\
\bf{P} \equiv \it{E}[\bf{(\hat x - x)}^2]](./db5acb046131c1321258ff1358cb82b2.png)
It would be very convenient to write the true state (xk) in terms of (x̂), in fact the previous hand-waving argument in support of equation (3.4) implies this must be possible.
Using the mapping defined in (3.7), the measurement equation is
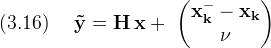
According to our least squares solution (3.10)
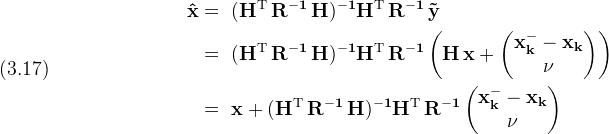
Putting this into the definition for (P)
![\displaystyle (3.18)\quad\
\begin{split}\
\bf P & =\
\it{E}[(\bf{\hat x - x})^2]\
= \it{E} \left[ \left(\
\bf{(H^{\rm T}\,R^{-1}\,H)^{-1} H^{\rm T}\,R^{-1}\
\begin{pmatrix} \bf{x_k^- - x_k} \\ \bf \nu \end{pmatrix}\
}\right)^2 \right]\\\
& = \bf{\
\left( \bf{(H^{\rm T}\,R^{-1}\,H)^{-1}H^{\rm T}\,R^{-1}} \right)\
\it{E} \left[\
\begin{pmatrix} \bf{x_k^- - x_k} \\ \bf{\nu} \end{pmatrix}^2\
\right]\
\left(\
\bf{(H^{\rm T}\,R^{-1}\,H)^{-1}H^{\rm T}\,R^{-1}}\
\right)^{\rm T}}\\\
& = \bf{\
\left( (H^{\rm T}\,R^{-1}\,H)^{-1}H^{\rm T}\,R^{-1} \right)\
\,R\,\
\left( (H^{\rm T}\,R^{-1}\,H)^{-1}H^{\rm T}\,R^{-1} \right)^{\rm T}}\\\
& =\
(\bf{H^{\rm T}\,R^{-1} H})^{-1}\
\end{split}](./a1ca6e5383ac598a55b15b666813afac.png)
Substituting back the values for (H) and (R) from (3.7)
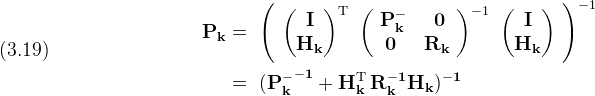
Equation (3.19) performs the "measurement update" for the state
error estimate (P).
It can be written as a parallel sum
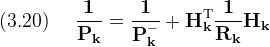
The last term in (3.20) can be considered to represent the extra information added to the state because of the current measurement.
The form of (3.20) makes sense because adding new information (positive (Rk-1)) will tend to decrease the system uncertainty.
Now all that remains is to derive the state error propagation equation. Again using definition (1.3)
![\displaystyle (3.21)\quad\
\bf P_{k+1}^- =\
\it{E} [ ( \bf{ x_{k+1}^- - x_{k+1} } )^2 ]](./c1721ce10d55d130efa9c997f0a61b16.png)
Applying the state propagation equation (1.1) to the inside of (3.21), the control input, being common, cancels out
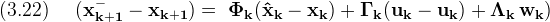
So
![\displaystyle (3.23)\quad\
\bf{P_{k+1}^-} =
\it{E}[ \bf{ \Phi_k (\hat x_k - x_k)^2 \Phi_k^{\rm T} +\
\Lambda_k\,w_k^2\,\Lambda_k^{\rm T} +
\Phi_k (\hat x_k - x_k) w_k^2\,\Lambda_k^{\rm T} +
\Lambda_k\,w_k (\hat x_k - x_k)^2 \Phi_k^{\rm T} } ]](./14141501325346748bdb3f03b1fe59e1.png)
In (3.23) the expectation of the cross terms is zero because (xk) contains terms of (wk-1) only, and by the assumption that (w) is white noise.
![\displaystyle (3.24)\quad\
\it{E}[ \bf{ w_k\,w_{k-1} } ] = \bf 0](./96646ece0e8470af25710b1c5ec0c90b.png)
So finally
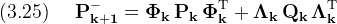
The derivation of the equations in table(2) is now complete.